
#이전 글
이 글은 스테이블 디퓨전 시리즈의 두 번째 글입니다.
이전 글을 먼저 보고 오시고 싶으신 분은 아래의 링크를 이용해 주세요.
들어가는 글

Model: ioliPonyMix
Prompt: made by da2el
AI 이미지도 하나의 ‘전문기술’의 영역
필자가 스테이블 디퓨전의 연재글을 쓰다보니 생각보다 ‘공부’가 된다.
AI 이미지를 생성한다는 건 단순히 마우스로 딸깍하며 이미지를 얻어내는 게 아니었다.
생각보다 고민할 거리와 연구할 거리가 많았다.
스테이블 디퓨전은 어떻게하면 더 좋은 이미지를 얻을 수 있는지 끊임없이 욕심이 나게 한다.
영어로 된 사이트를 뒤지거나 ChatGPT에 물어가며 이 기술에 대해 파헤치다보니, 다양한 ‘학습 모델’과 유래에 관한 지식까지 자연스럽게 파고들게 되었다.
그렇다. 스테이블 디퓨전(약자로는 SD)은 알아야 할 전문용어가 꽤 많다.
SDXL, VAE, Pony Model 등, 필자도 아직 남들에게 설명하기 어려운 용어가 부지기수다.
물론 처음부터 모든 용어를 알 필요는 없겠지만, 최소한 이 기술을 활용하기 위한 기본 기능에 관한 용어는 알 필요가 있다는 생각이 들었다.
스테이블 디퓨전 txt2img에 관해 안내하는 글은 다른 곳에서도 흔히 찾아볼 수 있지만, 필자는 이번 글을 통해 필자와 같은 ‘초심자’도 빠른 시간 안에 좋은 퀄리티의 이미지를 얻을 수 있다는 것을 몸소 보여주고자 했다.
그래서 이번 글은 용어를 안내하는 글이기도 하지만, 필자가 어떤 시행착오를 거쳐 점점 더 좋은 그림을 얻어가는지에 대해서도 볼 수 있을 것이다.
txt2img 탭에서는 텍스트를 기반으로 이미지를 생성할 수 있다.
그래서 txt2img라는 이름 그대로 “Text-to-Image”인 것이다.
처음에는 txt2img에서 쓰이는 용어만 알아두어도 이미지 생성에 문제는 없다.
txt2img에 쓰이는 용어만 잘 알아두어도 이후 추가 기능을 습득하기에 큰 무리가 없다.
물론 다른 사람들이 만드는 고퀄리티의 이미지를 만들기 위해서는 더 많은 학습이 필요하다.
이번 글은 스테이블 디퓨전에서 좋은 결과물을 내기 위한 기본적인 기능을 안내한다.
학습 모델 결정
Stable diffusion checkpoint에 활용할 모델 정하기

가장 먼저 Stable diffusion checkpoint를 설정해야 한다.
스테이블 디퓨전을 처음 설치하면, SD1.5만 달랑 주어진다.
이 학습 모델로는 ‘미소녀’를 뽑아낼 수 없다.
사실상 구세대 학습 모델이라고 봐도 될 정도로 이미지의 퀄리티가 떨어진다.
필자는 ‘아름답지 않은 모델’을 더 이상 활용할 생각이 없었으므로, 애니메이션풍 AI 이미지 생성에 최적화된 학습 모델을 찾아 나섰다.
그리고 선택한 모델이 바로 ioliponymix_v2이다.

위 링크에서 모델을 다운받을 수 있다.
학습 모델을 설치했다면, sd.webui 경로에 학습 모델을 붙여넣기 해야한다.
{설치 위치}/models/Stable-Diffusion에 파일을 넣으면 된다.
그 다음 ‘새로고침’ 버튼을 누르고 checkpoint에서 이번에 설치한 모델을 붙여넣기하면 된다.
상단 탭
정상적으로 모델을 세팅했다면, 이제 상단 탭부터 하나씩 설명하겠다.
이번 글은 txt2img의 기본 기능을 안내하는 게 주 목적이므로 주제에 벗어나는 내용은 다루지 않겠다.
(필요하다면 다음 글에서 다루도록 하겠다.)
가장 중요한 txt2img는 아래 목차 외에도 ‘프롬프트’와 ‘옵션’ 에서 더 자세히 설명한다.
txt2img

txt2img 탭에서는 프롬프트 텍스트를 기반으로 이미지를 생성할 수 있다.
정교한 결과물을 내기 전에 빠르게 수십 장의 러프스케치를 뽑아낼 때 유용하다.
스테이블 디퓨전에서 가장 자주 활용하는 기능이다.
img2img(Image to Image; I2I; ItI)
img2img 탭에서는 내가 따로 불러온 이미지와 프롬프트에 입력한 텍스트를 기반으로 이미지를 생성할 수 있다.
txt2img탭에서 생성한 이미지를 정교하게 다듬을 때도 활용할 수 있으며, 사진이나 3D 모델링을 이용해 이미지를 생성할 수 있다.
마음에 드는 캐릭터를 일관되게 생성할 때나 특정 포즈를 취하는 이미지를 생성할 때 유용하다.
이번 글에서는 따로 설명하지 않는다.
그 외(Extras, PNG Info 등등)
나머지 기능은 확장 기능으로, 조금 더 고급 사용자가 되면 다루게 된다.
이번 글의 목적은 기초 기능을 설명하는 것이므로 이번 글에서는 다루지 않는다.
txt2img 기초 기능 – 프롬프트

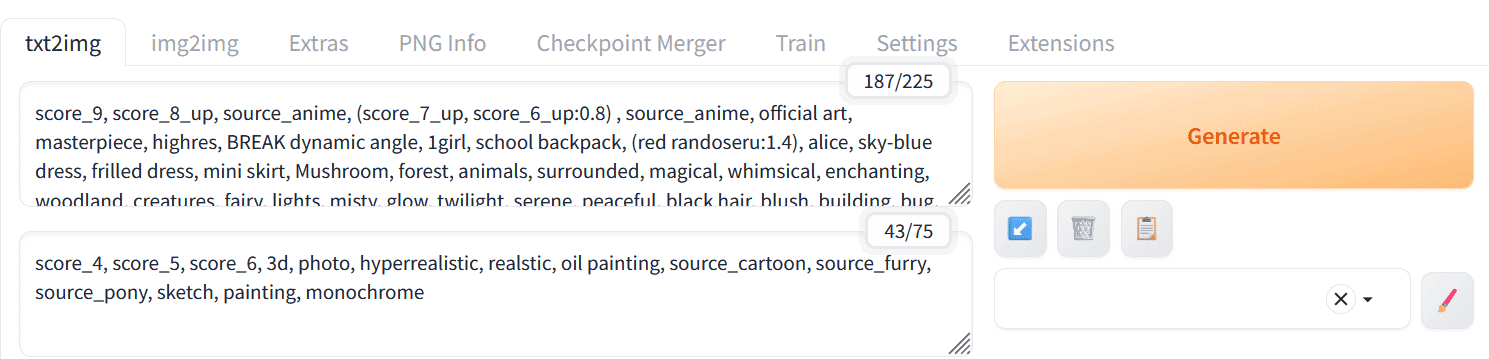
위 프롬프트는 da2el 님의 그림을 얻기 위해 사용된 프롬프트
먼저 스테이블 디퓨전 기초 기능 중에서 가장 자주 쓰이는 txt2img에 대해 알아보자.
이곳에서는 이미지를 대량으로 생성하고 뽑아내는 데 유용하다.
프롬프트라고 부르는 영역에 내가 원하는 텍스트를 넣고, 네거티브 프롬프트에는 내가 원하지 않는 텍스트를 넣는다.
내가 원하는 이미지를 얻을 때까지 프롬프트를 추가/수정/삭제하거나 기타 설정값을 조정하며 이미지를 대량으로 생성하기 좋다.
프롬프트(Prompt)
score_9, score_8_up, source_anime, (score_7_up, score_6_up:0.8) , source_anime, official art, masterpiece, highres, BREAK dynamic angle, 1girl, school backpack, (red randoseru:1.4), alice, sky-blue dress, frilled dress, mini skirt, Mushroom, forest, animals, surrounded, magical, whimsical, enchanting, woodland, creatures, fairy, lights, misty, glow, twilight, serene, peaceful, black hair, blush, building, bug, butterfly, dress, flower, frills, hair ornament, long hair, nature, outdoors, plant, purple flower, sitting, solo, sunlight, tree, white dress, looking at viewer, seductive smile위 프롬프트를 이용해 필자가 만든 이미지를 만들 수 있다.
스테이블 디퓨전 기초 기능에서 반드시 알아두어야할 용어를 꼽자면 프롬프트(Prompt)가 있다.
프롬프트에는 내가 원하는 키워드를 삽입해서 이번에 생성한 그림이 내가 원하는 결과물에 ‘가까워지도록’ 유도할 수 있다.
프롬프트는 영어로 적어야 한다. 한국어를 지원하는 경우도 있지만, 학습 모델이 학습한 자료가 대부분 영어라고 한다.
프롬프트에 뭘 적어야할지 모르겠다면 가장 쉬운 방법은 ‘남이 쓰던 것을 복사‘하는 게 좋다.
백지에서부터 어렵게 시작하지 말고, 남이 미리 생성해둔 프롬프트를 가지고 내가 원하는 요소를 넣거나 내가 원치 않는 요소를 조금씩 제외해보도록 하자.
몇 번 반복하다보면 프롬프트에 뭘 적어야할지 점점 감이 오게 될 것이다.
네거티브 프롬프트(Negative Prompt; 네거티브;네거)
score_4, score_5, score_6, 3d, photo, hyperrealistic, realstic, oil painting, source_cartoon, source_furry, source_pony, sketch, painting, monochrome위 네거티브 프롬프트를 이용해 필자의 이미지처럼 네거티브한 요소를 제외시킬 수 있다.
네거티브 프롬프트에 입력한 키워드는 이번에 생성한 그림이 내가 원하지 않는 결과물에서 ’멀어지도록‘ 유도한다.
앞서 설명한 프롬프트와 마찬가지로 네거티브 프롬프트도 영어로 적는 게 좋다.
네거티브 프롬프트에 주로 적게 되는 것은 나쁜 결과물을 만드는 요소들(손가락이 여섯 개거나, 신체 결손이 있는 등)을 방지하는 키워드가 된다.
또한, 결과물 안에 원하지 않는 요소들(예: 배경, 문자, 프레임, 스케치 선 등등)이 섞이는 것을 방지하는 데도 유용하다.
물론 네거티브 프롬프트에 이런것을 적는다고 모든 네거티브 요소를 제외하기는 어려울 수 있다.
그렇다고 언제까지나 네거티브 프롬프트를 제외하고 결과물을 생성한다면 좋은 결과물을 얻기 어려울 것이다.
추천하는 방법은, 일종의 ’답안지‘처럼 네거티브 프롬프트용 텍스트를 따로 메모해두고, 새로운 그림을 생성할 때마다 붙여넣는 것이다.
여기까지가 스테이블 디퓨전에서 꼭 알아야하는 기능이다.
(물론 프롬프트를 저장하는 기능이 따로 있다. 이는 다른 글에서 후술한다.)
txt2img 기초 기능 – 옵션

위 이미지는 필자가 위의 프롬프트를 이용해서 출력한, 초기 세팅에서의 이미지.
스테이블 디퓨전 기초 기능에서 꼭 알아야할 내용은 위의 프롬프트가 전부다.
하지만 그것만 알아서는 좋은 결과물을 내기에는 다소 부족하다는 느낌을 받을 것이다.
이제부터 우리는 결과물의 ‘방향성’을 조정하기 위한 몇 가지 요소들을 함께 알아볼 것이다.

2024년 6월 기준으로, txt2img에는 크게 총 11개의 매개변수가 존재한다.
버전업에 따라 위의 버튼 중에서 사라지는 게 생기거나 늘어나는 게 생길 수 있음을 양해 부탁드린다.
1. Sampling method
스테이블 디퓨전의 원리는 프롬프트에서 지정한 벡터(양과 음의 프롬프트)를 어지럽게 섞어두고, 그것을 깨끗하게 ‘닦아나가며’ 결과물을 뽑아낸다고 이해하면 쉽다.
샘플링 메소드는 깨끗하게 ‘닦는’ 방식을 말한다.
우리는 청소를 할 때 빗자루질을 할 수도 있지만, 물청소를 하거나 알코올 세정제나 티슈로 닦아낼 수도 있다.
마찬가지로, 샘플링 메소드에서 결정한 방식대로 결과물이 ‘잘 닦여’ 나오게 될 것이다.
청소 방식이 다르면 청소에 걸리는 시간이 달라지듯이, 샘플링 메소드가 달라지면 이미지 생성 속도도 달라진다.
따라서 현재 주어진 여건(양이나 질이냐), 그리고 목적(비슷한 이미지냐, 변동성이 큰 이미지냐)에 따라서 샘플링 메소드를 조정하게 된다.
기억할 건 두 가지다.
- 끝이 ‘a’ 문자를 포함한 샘플링 메소드는 변동성을 크게 준다.
- 스피드와 퀄리티 양쪽 다 좋은 평가를 받는 Euler a, DPM++ 2S a Karras, DPM++ 2M SDE Heun 등을 추천
2. Schedule type
txt2img에서 가장 최근에 생긴 기능 중 하나다.
학습률을 조정하기 위해 어떠한 전략을 취할지 결정하는 인자값이다.
가령, Uniform은 균등한 비율을, Exponential은 지수함수 비율로 학습률을 조정한다.
기존에는 스케줄러가 Sampling method에 종속되어있었으나 24년도 4월에 따로 분리되었다.
automatic, uniform, karras, exponential, polyexponential, sgm uniform 등이 있으며 주로 karras가 사용된다.
참고로 karras는 Nvidia의 한 머신러닝 엔지니어 이름이다.
기억할 건 아래와 같다.
- DPM++ 2M SDE Karras처럼, Sampling method와 같이 묶여서 불린다.
- 모르겠으면 Automatic이나 Karras로 지정한다.
3. Sampling Steps
몇 번의 ‘닦아내기’를 할지 결정한다.
기본값대로 20으로 둬도 되지만, 조금 더 시간을 들이고 싶다면 30 정도로 둬도 괜찮다.
무조건 높다고 퀄리티가 좋아지지는 않는다. 40 이상은 결과물이 크게 달라지지 않는다고 한다.

고퀄리티라고 보기는 어려운 결과물이 나왔다.
4. Hires. fix

txt2img에서 생성한 이미지를 업스케일링을 하여 고해상도로 만들어준다.
txt2img의 이미지가 어느 정도 컨셉이 잡히면 Hires. fix 옵션을 이용해서 고퀄리티로 만들어볼 수 있다.
단순히 업스케일링만 이루어지는 게 아니라 그림의 디테일이 더욱 정교해지고 퀄리티 차이가 크게 나므로 웬만한 완성도 높은 그림은 Hires. fix를 거친다고 볼 수 있겠다.
특히 img2img 등에서 퀄리티 업을 할때 활용된다.
Upscaler 알고리즘을 선택하여 이미지를 키울 수도 있지만, VRAM을 많이 사용하므로 자신의 PC 상황에 맞게 활용하면 좋다.
자세한 건 다음 글에서 후술한다.
5. Refiner

스테이블 디퓨전(SD)에는 전처리와 후처리에 각각 다른 학습 모델을 사용할 수 있다.
예를 들어, 전처리 모델에는 ‘비율에 특화된’ 모델을 쓰고, 후처리 모델에는 ‘손가락 정교화’에 특화된 모델을 쓸 수 있다.
이 후처리를 하는 학습 모델을 지정할 때 Refiner를 사용하게 된다.
Refiner를 사용한다고 해서 반드시 나은 결과를 얻는 건 아니니 명확한 목적성이 있을 때 활용하면 좋을 듯하다.
6. Width, Height
학습 모델이 ‘학습’ 및 ’생성‘하는 결과물의 크기이다.
512×512, 768×768 사이즈가 아닌 사이즈로 이미지를 생성하면 ’학습된 데이터‘가 적어 좋은 결과물이 나오기 힘들다.
또한 이미지 사이즈가 클수록 GPU VRAM의 부하가 커지기 때문에 그래픽카드 성능에 따라서는 결과물을 뽑아내지 못할 수도 있다.
일반적으로는 작은 해상도 이미지를 생성한 뒤, 업스케일링 기술로 이미지를 확대하는 방식이 많이 사용된다.
7. Batch count


한 번의 실행으로 생성하려는 이미지의 개수이다.
스테이블 디퓨전은 기본적으로 이미지를 1장씩 순차적으로 생성한다.
Batch count가 4이면, 1, 2, 3, 4번 이미지 순으로 이미지가 생성된다.
생성이 완료되면, 생성한 이미지 개수만큼 합쳐진 이미지 1장과 각각 생성된 낱장의 이미지가 만들어진다.
입력한 프롬프트가 내가 원하는 결과물에 가깝게 나올지 아닐지 첫 생성 시에는 판단하기 어려우므로 처음부터 높은 숫자를 주는 건 추천되지 않는다. 초기 생성 시에는 1~4 정도가 적정하다.
내가 원하는 이미지에 가까운 이미지를 얻었다는 판단이 서면, Batch count를 16 이상으로 높여 내가 원하는 이미지에 더욱 가까운 이미지를 얻을 때까지 대량생산할 때 유용하다.
8. Batch size

동시에 생성할 이미지의 개수이다.
Batch count는 순차생성하지만, Batch size는 동시생성한다는 차이가 있다.
결과물은 Batch Count와 마찬가지로, 생성이 완료되면 생성한 이미지 개수만큼 합쳐진 이미지 1장과 각각 생성된 낱장의 이미지가 만들어진다.
동시에 생성하기 때문에 당연히 속도 면에서 Batch Count보다는 다소 빠르지만, 그래픽카드의 VRAM이 높지 않다면 낮은 수로 두는 것을 권장한다.
9. CFG Scale
CFG는 Classfier-free Guidance라는 뜻으로, ’분류기-무시 수치값‘이라고 한다.
스테이블 디퓨전에서는 학습 모델과 분류기를 이용해 텍스트로부터 이미지를 생성한다. 이 ’CFG Scale‘값이 클수록 분류기의 영향력이 감소하여 프롬프트의 영향력이 높아진다.
쉽게 말해, 이미지의 다양성이 줄어들고 비슷한 이미지가 생성되는 경향성이 높아진다.
CFG Scale값이 낮아지면 분류기의 영향력이 커져, 프롬프트에 넣지 않은 불필요한 ’노이즈‘가 끼어들 가능성이 높아진다.
7~12 정도의 수치 내에서 수치를 조정해가는 것은 크게 문제가 없다.
이번 글에서는 10으로 고정하여 사용하였다.
10. Seed
스테이블 디퓨전은 ’난수 기반’으로 랜덤한 이미지를 생성한다. 여기서 시드는 ‘난수값’을 말한다.
기본값 -1(주사위 버튼)은 완전한 무작위값을 자동으로 넣어준다.
시드값을 고정하기 위해 재활용 버튼을 누르면 동일한 구도나 이미지를 얻을 수 있다.
주사위 버튼을 누르면 시드가 -1(무작위)로 설정된다.
11. Script
프롬프트에 조합을 더하거나 어떠한 설정적 변형을 주고자 할때 사용한다.
일반적으로는 건드릴 일은 없다.
하지만 설명을 위해서 필자는 일부러 건드려보았다.
필자가 Script에서 만져본 기능은 X/Y/Z plot이다.
각 값을 위와 같이 지정하고, VAE에 SDXL_VAE를 적용했다.
(VAE 등 이번 글에서 소개하지 않은 내용은 다음 글에서 후술한다.)
그러자 아래와 같은 이미지를 얻게 되었다.

Script에 있는 기능은 이런 식으로 사용한다는 점을 보여주고자 첨부하였다.
정리하는 글

고작 몇 시간의 공부와 노력 만으로도 위와 같은 고퀄리티의 이미지를 얻었다.
아직은 기본 기능밖에 활용하지 못하는 탓에 원하는 구도나 사물의 배치를 지정하기는 어렵지만, 앞으로 차차 더 배워나가는 과정을 다음 글에서도 연재할 계획이다.
모델은 위의 ioli 외에도 pony나 SDXL, SD3.0 등 다양한 모델이 존재한다.
이러한 ‘학습 모델’을 설치할 수 있는 AI 이미지의 대표 허브격인 두 사이트를 소개하며 글을 마친다.



답글 남기기