
![[comfyui] 서브컬처풍 게임 미소녀 일러스트 만들기 With Illustrious](https://subculturegamer.com/wp-content/uploads/2026/04/comfyui-서브컬처풍-게임-미소녀-일러스트-만들기-with-illustrious-1024x1024.png)
들어가는 글
최근 생성형 AI를 실무에 적용하려는 움직임이 눈에 띄게 늘고 있다.
LLM 등을 이용해 게임 스크립트를 쓰려고 하거나, Stable Diffusion 등으로 게임 일러스트를 생성하는 일 등이다.
클로드 코드(Claude Code)를 사용하면 프로그래머가 아닌 사람도 하루 안에 원하는 앱을 만들 수 있는 세상이다.
ComfyUI는 한 마디로 Stable Diffusion의 기능을 더 강화한 노드 방식의 이미지 생성형 인공지능이다.
Stable Diffusion(이하 SD)와 사실상 같은 기능을 제공하는데, 이쪽이 더 시각적으로 직관적이고 속도도 빠르며 다양한 옵션을 제공한다.
사실상 SD의 상위호환이라고 말해도 무방할 듯 싶다.
아마 앞으로는 Stable Diffusion Web UI보다는 ComfyUI를 쓰는 사람이 더 많아지지 않을까?
그러니 이번 글도 ComfyUI를 이용해서 이미지를 생성하는 방법을 소개하게 되었다.
ComfyUI의 쓸모
시각적인 자료는 원하는 아이디어를 직관적으로 보여주면서, 최대한 오해없이 전할 수 있어 든든하다.
그럴 때 ComfyUI는 내가 원하는 이미지를 가장 확실하게 전달할 수 있는 도우미가 되어줄 수 있다.
ComfyUI를 이용해서 할 수 있는 일은 대표적으로 아래와 같다.
- 프롬프트를 이용한 캐릭터, 배경, 아이콘 등 리소스 생성
- 캐릭터 컨셉 원화 시트 생성
- 캐릭터 풀 컷 일러스트 생성
- 레퍼런스 이미지로 캐릭터 포즈나 구도 등을 지정한 이미지 생성
- 여러 캐릭터가 등장하는 이미지 생성
그 밖에도 ComfyUI의 활용 범위는 무궁무진하니, 원한다면 더 찾아봐도 좋을 것이다.
실무에서는 ‘레퍼런스 수집’에 많은 시간을 할애할 수 밖에 없다.
구글 검색이나 핀터레스트에서 원하는 이미지를 찾게 되는데, 시간은 무한대가 아니기에 어느 정도 시점에 결국 타협을 해야 한다.
게다가 레퍼런스 이미지를 2~3장 이상 첨부하다 보면, 보는 사람으로 하여금 오히려 혼동을 줄 수도 있다.
가령 ‘레퍼런스 A’와 ‘레퍼런스 B’는 서로 화풍이나 포즈 등 특징이 확연하게 다른 경우, 각각 얼마나 어떻게 원하는 작업물에 반영이 되면 좋을지 설명하기 때문이다,
이럴 때 ComfyUI는 이러한 시행착오와 커뮤니케이션 비용을 확실하게 줄여줄 수 있다.
이 글의 목적

이번 글은 ComfyUI를 설치부터 실행까지 가이드하는 게 목적이 아니다.
이미 그런 글은 다른 곳에서 많이 다루고 있는 데다, 필자의 블로그에 오는 사람이라면 단순한 설치글보다는 보다 실용적인 활용팁을 찾아 오실 거라고 생각했다.
ComfyUI를 이용한 강좌는 많지만 의외로(?) 서브컬처풍 게임 캐릭터를 만드는 방법을 잘 정리한 글이 없었다.
과거에 Stable Diffusion은 써봤지만, ComfyUI가 낯선 사람을 위해서도 ComfyUI를 이용한 캐릭터 메이킹 가이드 글이 필요할 것 같았다.
이번 글에서는 ComfyUI를 이용해서 서브컬처풍 게임 캐릭터를 만드는 방법을 안내하려고 한다.
이 글을 읽으면서 따라한다면 누구나 ComfyUI로 서브컬처 모바일 게임 일러스트 같은 결과물을 직접 만들어낼 수 있을 것이다.
ComfyUI 사전 세팅
따로 설치 방법을 안내하지는 않더라도, ComfyUI를 실행하기 위한 최소한의 권장 사항은 미리 일러둔다.
ComfyUI 권장사양
| 구성 요소 | 최소 사양 | 권장 사양 (원활한 환경) |
|---|---|---|
| GPU | NVIDIA 그래픽 카드 (4GB VRAM) | NVIDIA RTX 3060 12GB 이상 |
| VRAM | 4GB~8GB | 12GB~24GB (FLUX 및 영상 작업 시) |
| RAM | 8GB~16GB | 32GB 이상 |
| CPU | Intel Core i5 / AMD Ryzen 5 이상 | 12세대 Intel Core i5 / Ryzen 5 이상 |
| 저장소 | 500GB SSD | NVMe SSD |
ComfyUI는 ‘다양한 샘플을 얻기 위해’ 수많은 시행착오를 해야 하는 프로그램이다.
무슨 말인가 하면, 하나의 결과물을 얻기 위해 적어도 수십에서 수백 번 프롬프트나 LoRA를 만지며 계속 미세조정을 해야한다는 의미이다.
정해진 시간 안에 최대한 많은 결과물을 얻으려면 PC 성능이 좋을 수록 좋다.
GPU와 GPU의 VRAM이 중요한데, ‘이미지’를 생성하는 기술이다보니 이에 직결되는 GPU의 성능은 곧 ComfyUI의 효율성과 연결된다.
위에 권장 사양을 적어두긴 했지만, 가급적이면 표의 권장 사양보다 더 좋은 PC 세팅을 권장한다.
ComfyUI를 많이 사용할 거라면 자신이 AMD 매니아라고 해도 GPU만큼은 NVIDIA GPU 사용을 권장한다. ComfyUI가 NVIDIA 기반 위에서 세팅되어 있어 가장 안정적이고 최적화되어있기 때문이다.
참고로, 필자의 테스트 환경은 아래와 같다.
- CPU: AMD Ryzen 5 5600X (OC)
- Board: TUF GAMING B550M-PLUS
- Memory: DDR4 32GB
- GPU: NVIDIA GeForce RTX 3080
- SSD: NVMe 3.0
PC 사양이 위 테스트 환경보다 좋고 나쁨에 따라서 결과물을 받는 속도가 달라질 수 있음을 미리 참고하자.
ComfyUI 설치 방법
- 공식 다운로드 페이지: https://www.comfy.org/download
- 다운로드 안내글 링크: https://damoang.net/free/5151109(다른 블로그)
ComfyUI 설치 관련 팁
- 사전에 용량을 넉넉히 확보해두는 게 좋다. (300GB 바이트 이상) ComfyUI 설치 및 관련해서 필요한 모델을 설치하다보면 100GB는 우습게 차지한다.
- 설치하는 공간은 HDD보다는 SSD, 일반 SSD보다는 NVMe SSD를 권장한다. 작업 속도에 영향을 준다.
- 가급적이면 설치 경로는 ‘심플한 곳’이 좋다. 다양한 모델을 설치하게 되는데, 설치한 파일의 경로를 옮길 때, 설치 경로 찾기가 쉬울수록 스트레스를 덜 받는다.
제로부터 시작하는 캔버스 생활
ComfyUI를 제로부터 시작하게 되면 위처럼 빈 캔버스 상태에서 시작한다.
우리는 위 캔버스의 임의의 지점을 더블 클릭하여 ‘노드’를 만들 수 있고, 각 노드를 연결하여 원하는 기능을 추가/보강/임시제외/삭제 할 수 있다.
일단 위 캔버스 상태에서는 아무 것도 할 수 없으니 ComfyUI는 잠시 종료하도록 하자.
최종 결과물
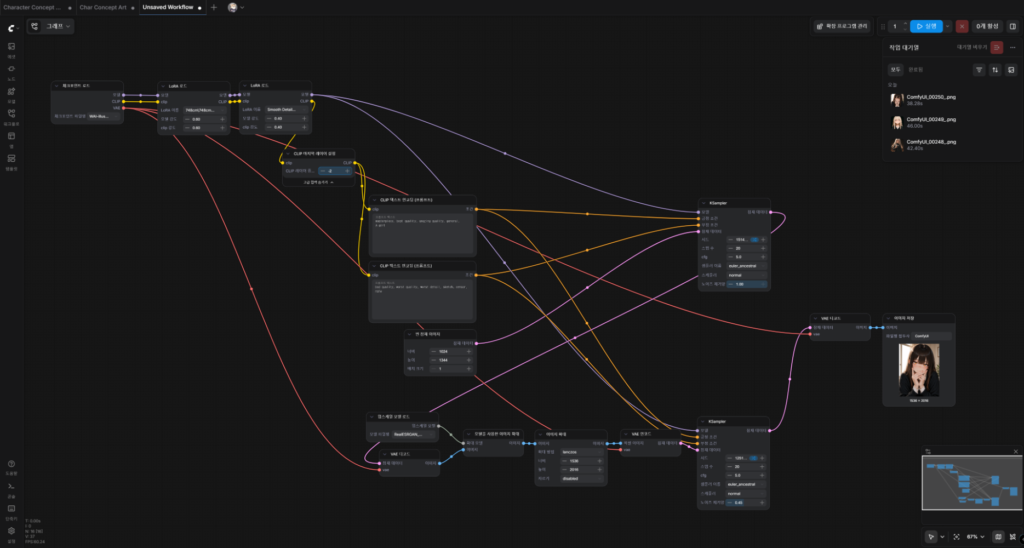
우리가 최종적으로 세팅할 공간은 위와 같다.
물론 노드의 생김새나 기타 세팅값은 달라질 수 있어도, 대략 위처럼 구성하면 ‘미소녀 캐릭터 생성’에는 크게 문제가 없다.
그렇다면 위처럼 세팅하기 위해 필요한 것들을 하나씩 갖춰보도록 하자.
(만약 이미 ComfyUI 세팅을 완료하신 분이라면, 위 이미지처럼 노드를 연결하시고 원하시는 프롬프트를 입력해서 결과물을 받아 보셔도 좋을 것 같다.)
미소녀 생산 공장 만들기
ComfyUI는 강력한 툴이지만, 그 자체로는 원하는 결과물을 얻어낼 수 없다.
‘모델(Models)’이라고 하는 것을 받아서 그것을 노드로 연결해야 하기 때문.
여기서 ‘모델’이라는 개념은 ComfyUI를 돌리기 위해 필요한 각 ‘요소(elements)’라고 보면 된다.
후술할 체크포인트(checkpoint), 로라(LoRA), 컨트롤넷(controlnet) 등도 모두 ‘모델’이다.
모델을 받는 곳은 여러 군데가 있는데, 필자는 Civitai를 기준으로 설명하도록 하겠다.
체크포인트 설치하기
위 경로로 이동한다. 미리 가입을 해두는 것을 권장한다.
가입을 하지 않고 진행하다보면 위처럼 결국 ‘로그인’을 유도하는 창으로 이동하게 될테니 말이다.
참고로 Civitai는 26년 4월부터 성인 등급(NSFW) 콘텐츠는 따로 Civitai.red로 분리해서 관리한다.
일부 모델은 Civitai.red에서만 찾을 수 있기 때문에 만약 자신이 찾는 모델이 안보인다면 포기하지 말고 .red 홈페이지도 찾아보는 것을 권한다.
Civitai.red에서 볼 수 있는 모델은 Civitai.com에서도 볼 수 있다.
https://civitai.red/models/827184/wai-illustrious-sdxl?modelVersionId=2883731
우리가 받을 체크포인트는 바로 WAI-illustrious-SDXL이라는 이름이다.
이 모델은 이 글이 작성되는 26년 4월 26일 기준 v17.0까지 출시되었다.
최근 사용되는 체크포인트 중에서 가장 평가도 좋고 인기가 높은 모델이니 위 모델을 사용하겠다.
우측의 Download 버튼을 눌러 위 모델을 다운받도록 하자.
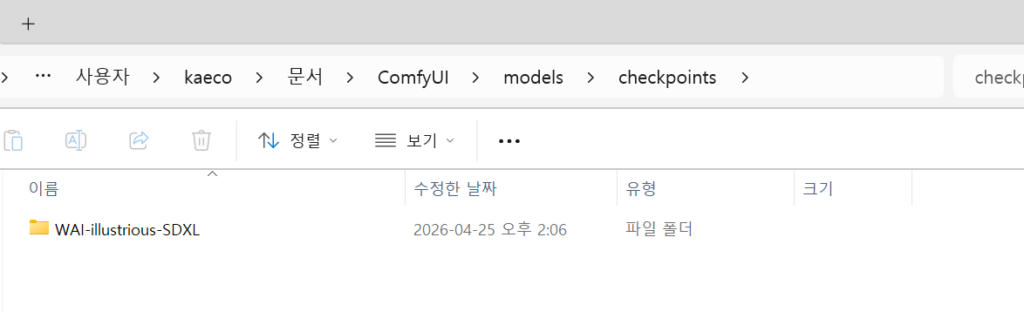
이제 ComfyUI를 설치한 경로로 이동한다.
\ComfyUI\models\checkpoints라는 경로로 이동한 뒤, ‘WAI-illustrious-SDXL’이라는 폴더를 만든다.
그리고 그 안에 해당 파일을 이동시킨다.

폴더 구조를 사용하는 이유는 종종 사용하던 모델의 새로운 버전이 나왔을 때, 구버전과 신버전을 비교-관리하기 위함이다.
이제 체크포인트가 ComfyUI에서 정상 확인되는지 ComfyUI를 기동해보자.
참고로, ComfyUI를 켜둔 상태에서 모델을 폴더에 추가하면 ComfyUI는 그것을 인식하지 못한다.
그래서 모델을 추가할 때마다 ComfyUI를 껐다가 켜줘야하는 번거로움이 있다.
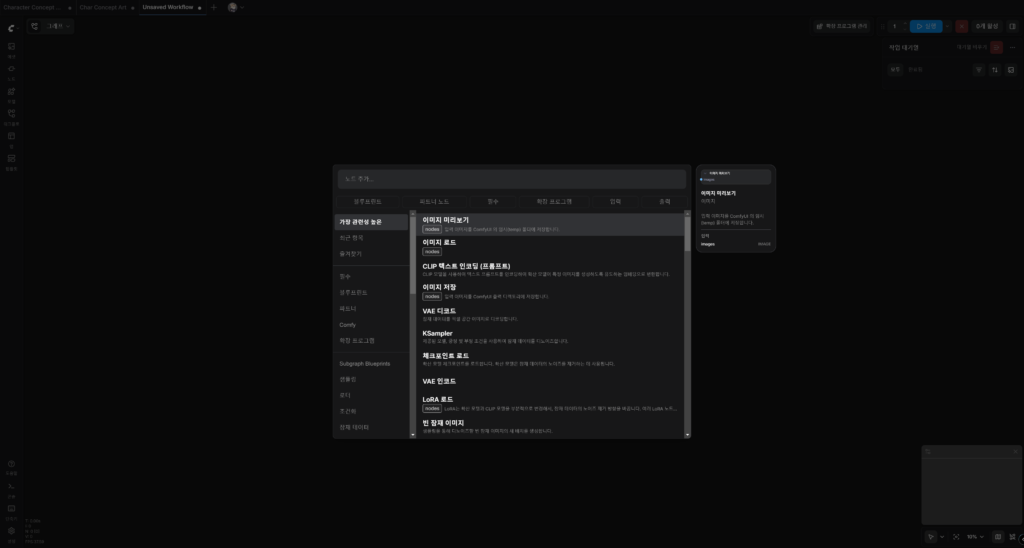
아까의 빈 캔버스로 돌아온다.
캔버스 내 임의의 영역에서 마우스를 두 번 클릭하면 위처럼 ‘노드 추가’를 할 수 있는 팝업이 뜬다.
한글로 ‘체크포인트 로드’ 또는 영어로 ‘checkpoint load’를 입력한 뒤, ‘체크포인트 로드’ 노드를 선택해 보자.
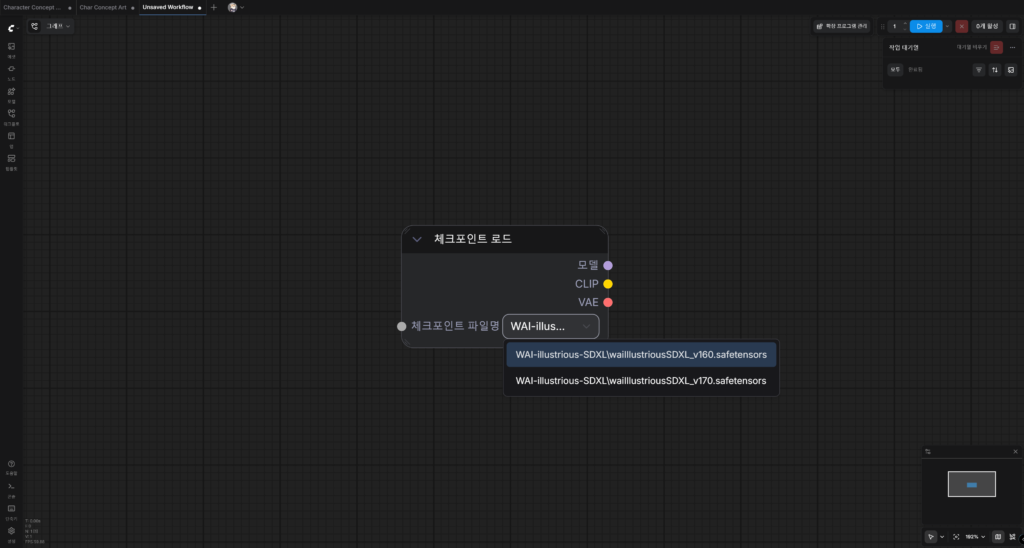
새로 만들어진 노드가 위처럼 ‘체크포인트 로드’라는 이름이고, 우측으로 ‘모델’, ‘CLIP’, ‘VAE’라는 손이 생긴 것을 확인할 수 있다.
가장 중요한 건, ‘체크포인트 파일명’에 아까 설치한 WAI-illustrious-SDXL이 연결되어있는지이다.
만약 아까 모델을 설치하고 \ComfyUI\models\checkpoints 경로로 파일을 옮겼는데도 뜨지 않는다면 엉뚱한 경로에 파일을 두었다는 뜻이니 다시 잘 찾아봐야 한다.
기본 노드 연결 공사하기
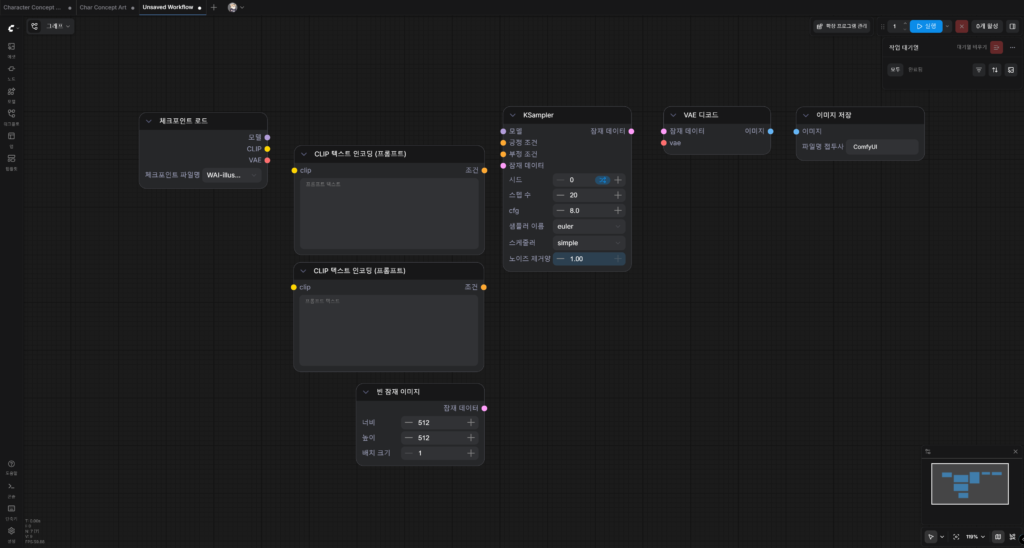
체크포인트 로드에 성공했다면, 이제 기본적인 노드 연결을 구성해볼 때다.
ComfyUI에는 다양한 노드가 존재하는데, 하나의 이미지를 만들기 위해서는 대략 위에 나열된 노드가 필요하다.
각 노드가 하는 일은 다음과 같다.
- 체크포인트 로드에서 AI 모델을 불러온다.
- CLIP 텍스트 인코딩에서 원하는 것/원하지 않는 것을 텍스트로 지시한다.
- 빈 잠재 이미지에서 결과물의 캔버스 크기를 정한다.
- KSampler가 모델, 프롬프트, 빈 캔버스를 받아 이미지를 생성한다.
- VAE 디코드가 생성된 데이터를 사람이 볼 수 있는 이미지로 변환한다.
- 이미지 저장으로 결과물을 파일로 저장한다.
각 노드는 왼쪽과 오른쪽에 ‘손’이 달려있는데, 그 노드가 가진 손을 잡을 수 있는 다른 노드도 있고 아닌 노드도 있다.
예를 들어, ‘체포크인트 로드’에 달려있는 ‘모델’이라는 손은 우측의 KSampler 노드의 왼쪽에 달린 ‘모델’ 손을 잡을 수 있다. (색상도 동일하다.)
하지만 동일한 ‘모델’이라는 손은 ‘CLIP 텍스트 인코딩’이나 ‘빈 잠재 이미지’, ‘VAE 디코드’ 등에는 연결할 수 없다.
한편 ‘체크포인트 로드’의 ‘CLIP’이라는 손은 CLIP 텍스트 인코딩의 clip 손을 잡을 수 있지만, KSampler 등 다른 노드와는 손을 잡을 수 없다.
글로만 보면 어려워보일 수 있겠으나, ComfyUI는 서로 연결할 수 있는 노드끼리는 자동으로 같은 색깔로 색칠해주기 때문에 같은 색깔끼리 연결만 하면 된다.
각 노드의 손을 모두 잡으면 대략 아래와 같은 형태가 된다.

정상 작동 여부 확인하기
노드 연결을 모두 마쳤다면 이미지를 생성할 수 있는 가장 기초적인 단계를 마친 셈이다.
집짓기로 비유하자면 이제 콘크리트까지는 부었기에 비는 피할 수 있는 단계라고 볼 수 있겠다. (그럼에도 아직 갈 길은 멀지만)
이제 CLIP 텍스트 인코딩 프롬프트에 아래와 같은 프롬프트를 입력해서 적상 작동하는지 테스트해보자.
- Positive: A girl
- Negative: (빈 칸)
이렇게 입력하고 화면 우측 상단의 ‘실행’ 버튼을 누른다. 만약 이때 오류가 난다면 노드끼리 제대로 연결이 안 된 것이다.
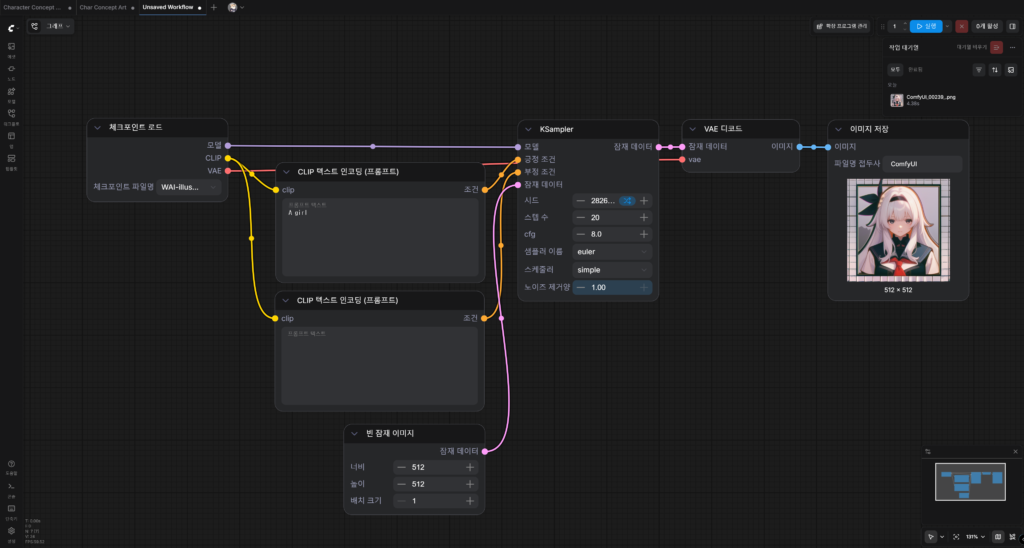
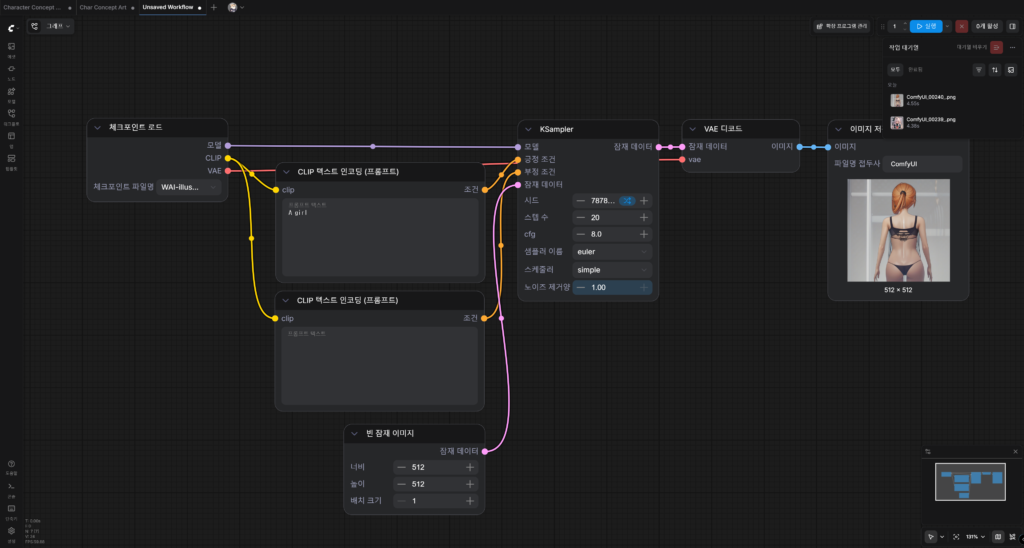
필자는 위 노드를 두 번 실행했다.
두 번 다 여성 캐릭터가 나오긴 했지만, 의도와는 다른 프레임이 생기거나 배경이 이상하게 깨지는 등 사실상 실사용이 어려운 수준의 이미지가 나왔다.
하지만 너무 실망하지 말자. 여기서 끝낸다면 ComfyUI의 진짜 실력을 아직 보지 못한 셈이다.
이제부터 위의 처참한(?) 결과물이 어떻게 바뀌어가는지 한 스텝씩 개선해보도록 하자.
미소녀 퀄리티 업을 향해서
체크포인트 권장 사양 적용하기
https://civitai.red/models/827184/wai-illustrious-sdxl?modelVersionId=2883731
가장 먼저 해야 할 일은, 아까 설치한 체크포인트의 설명서를 다시 꼼꼼히 읽어보는 거다.
방금 우리가 한 일은 체크포인트가 정상 작동하는지(오류가 없는지) 확인하는 것일 뿐, 아직 권장 사양을 적용하지 않았기 때문이다.
아래는 해당 체크포인트에서 권장하는 실행값이다.
Recommended settings:
Steps: 15-30
CFG scale: 5-7
Sampler: Euler a
The VAE is already integrated, please do not ask such questions anymore.
use size larger than1024x1024 for the original dimensions.
Example images use 1024×1344.Hires upscale: 1.5, Hires steps: 20, Hires upscaler: R-ESRGAN 4x+ Anime6B,Denoising strength: 0.35~0.5
There are four safety rating tags: general, sensitive, nsfw,explicit.
Users are expected to consciously add “nsfw” to negative prompts to filter inappropriate content.Positive Prompt
,masterpiece,best quality,amazing quality,Negative Prompt
bad quality,worst quality,worst detail,sketch,censor,
위 체크포인트에서 권장하는 대로, 한번 아까 완성한 노드에 하나씩 적용해보자.
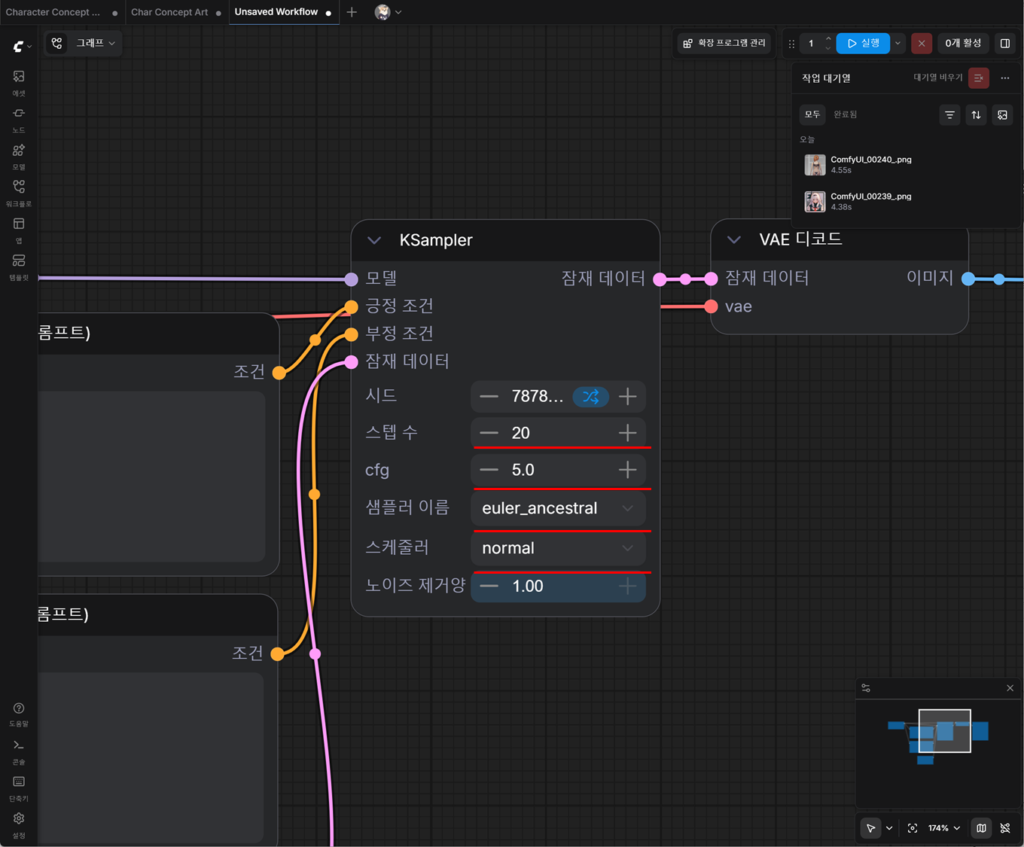
먼저 KSampler를 보자.
스텝 수를 20, cfg는 5.0, 샘플러 이름은 euler_ancestral, 스케줄러는 simple로 설정한다.
위에 적힌 Euler A라는 표현은 ComfyUI에서는 eiler_ancestral과 같은 의미이다.
스케줄러의 경우, 위의 가이드에서는 아무것도 적혀있지 않았는데, 그것은 기본값을 normal로 세팅하라는 의미이다.
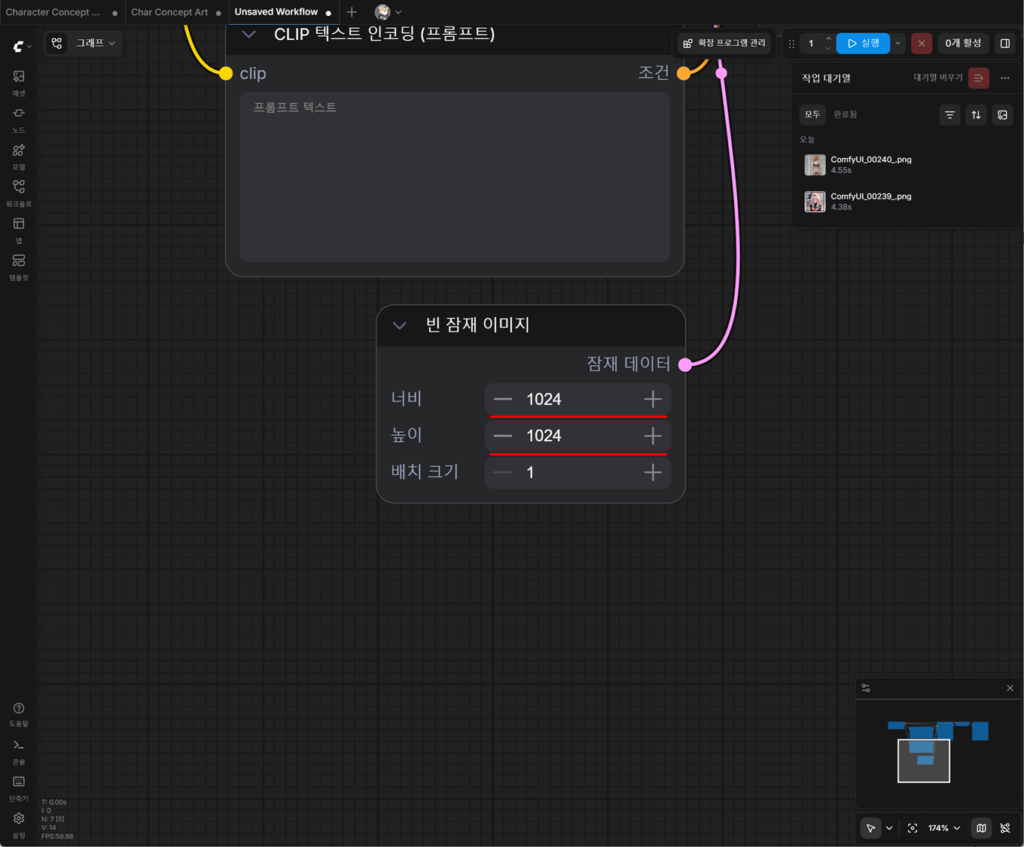
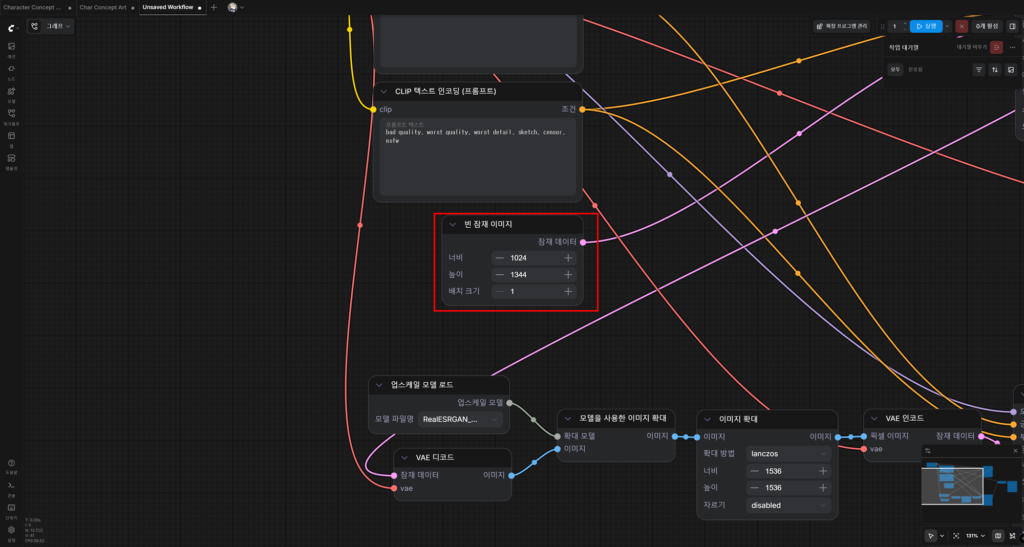
다음으로, 빈 잠재 이미지의 너비와 높이에 적혀있던 값을 1024로 바꾼다. (즉, 1024×1024 이미지를 결과물로 얻는다는 뜻)
배치 크기란, 한 번의 ‘실행’ 동안 생성하는 이미지의 수다. 나중에 대량 생산 공정에 들어갈 경우 수치를 바꿔줄 수 있겠지만 지금은 넘어가도 된다.
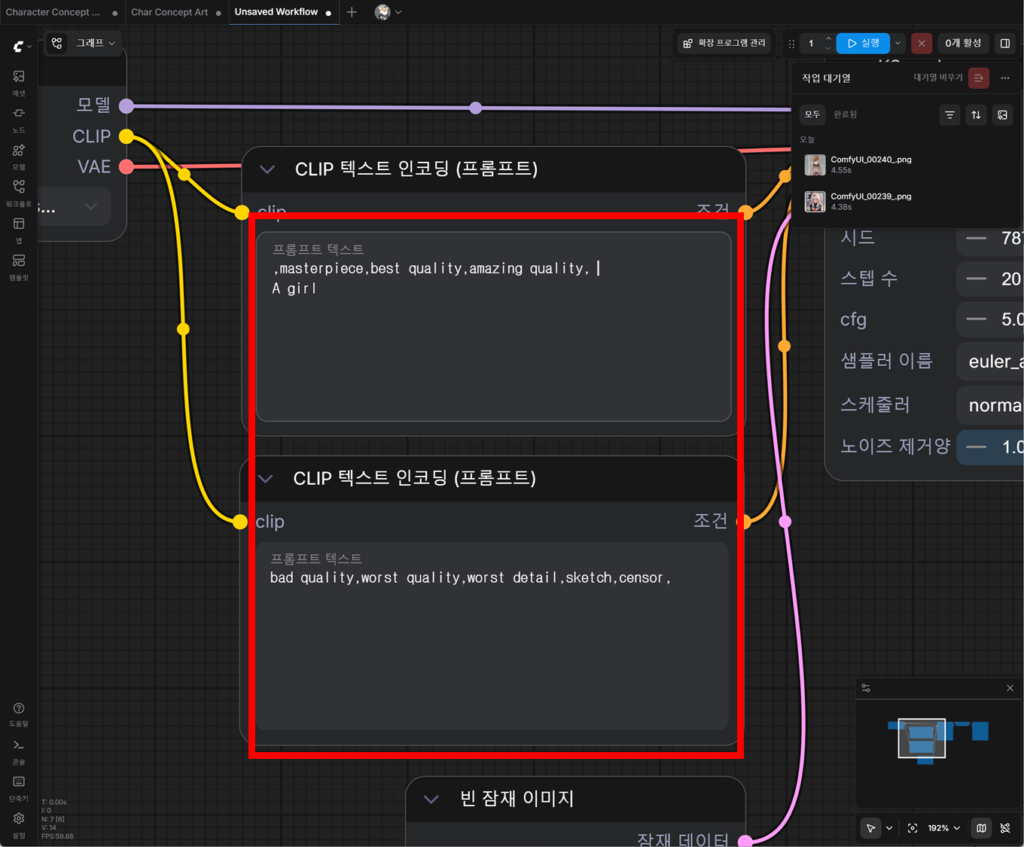
다음으로, CLIP 텍스트 인코딩을 위처럼 입력한다.
첫 줄에는 ‘퀄리티’에 영향을 주는 프롬프트를 입력하는 게 일반적이다.
특히 Positive 프롬프트에는 ,masterpiece,best quality,amazing quality, 를, Negative 프롬프트에는 bad quality,worst quality,worst detail,sketch,censor, 를 입력하면 퀄리티를 조금이라도 잡아주는 데 도움이 된다.
참고로, 쉼표(,) 기호 앞이 빈 칸이거나 공백이 하나 더 들어가 있거나 개행이 되어 있어도 퀄리티에 영향을 주지 않는다.
이제 여기까지 한 뒤에 한번 ‘실행’ 버튼을 다시 눌러보자.
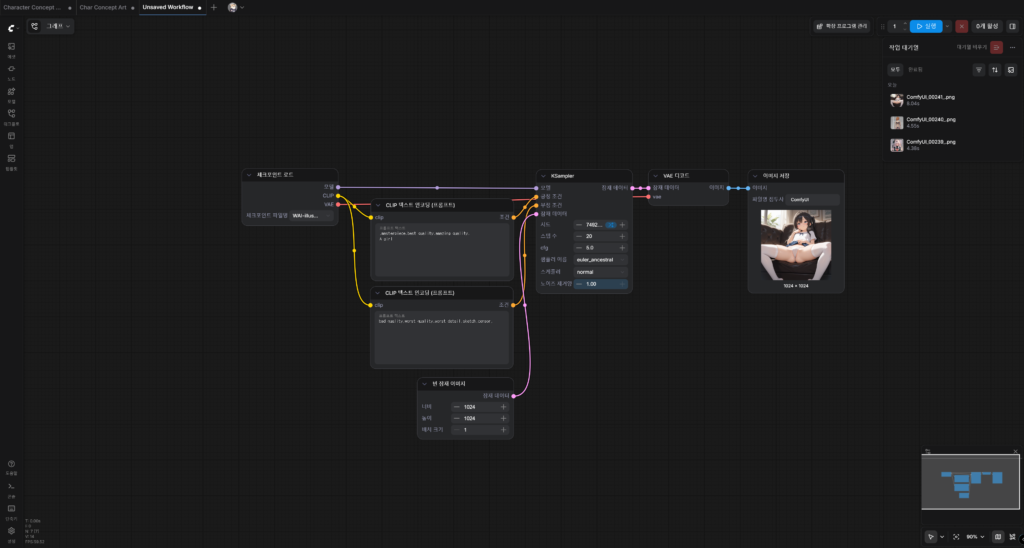
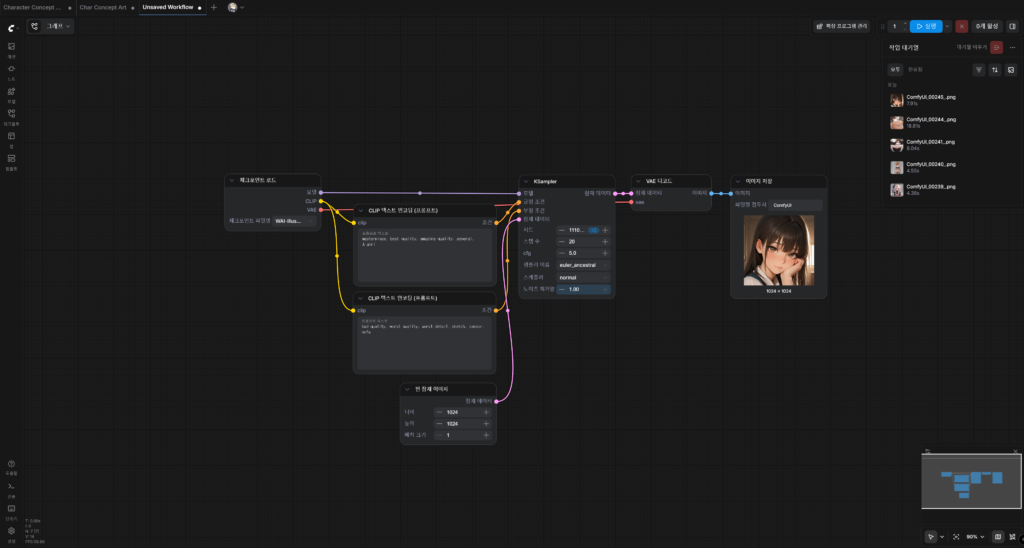
필자는 아까처럼 총 두 번을 실행했는데, 보다시피 캐릭터의 퀄리티가 확연히 증가한 것을 볼 수 있다.
첫 이미지에서 다소 수위가 아슬아슬한 이미지가 나오는 것을 알 수 있는데, 이 체크포인트가 NSFW 이미지도 생성할 수 있는 체크포인트이기 때문인 것으로 보인다. (그래서 civitai.com이 아니라 civitai.red에서 받을 수 있다.)
지금 NSFW 콘텐츠를 만드려는 게 아니므로, 긍정의 프롬프트에 general을, 부정의 프롬프트에 nsfw를 입력해주었다.
그러자 두 번째 이미지는 암젼하게 소녀의 초상화 이미지를 보여주었다.
이제 우리는 간단하게 ‘프롬프트’에 원하는 키워드를 입력하기만 해도 몇 초 안에 빠르게 원하는 수정사항을 적용할 수 있다.
Hires Fix와 업스케일
지금까지 진행한 것만으로도 캐릭터의 외양은 꽤 많이 개선되었지만, 아직 퀄리티를 높일 방법은 다양하게 남아 있다.
아까 우리가 확인했던 ‘체크포인트’에서도 아래처럼 Hires를 이용하여 예시 이미지를 만들었다고 적혀 있다.
Example images use 1024×1344.
- Hires upscale: 1.5
- Hires steps: 20
- Hires upscaler: R-ESRGAN 4x+ Anime6B
- Denoising strength: 0.35~0.5
즉, 이러한 Hires 수치를 적용한다면 우리가 원하는 퀄리티에 더 가까워질 것이라고 유추할수 있다.
여기서 우리가 알아야할 개념이 두 개가 있는데 바로 Hires Fix와 Upscale(업스케일)이다.
Hires Fix란 낮은 이미지의 이미지를 먼저 생성하고(예: 512×512), 그것을 업스케일해서 해상도를 키운 뒤 디테일을 추가하는 방식이다. 처음부터 고해상도 이미지를 생성하면 구도가 깨지거나 비율이 왜곡되는 등 이미지 품질 저하 문제가 생길 수 있는데, Hires Fix 방식을 사용하면 고해상도 이미지를 얻을 수 있으면서도 더 디테일이 훌륭한 결과물을 얻을 수 있다.
업스케일은 큰 틀에서 Hires Fix도 그에 속한다고 할 수 있지만, 기본적으로 이미지의 사이즈를 X2, X4배 등으로 키우는 기술이다.
업스케일에 특화된 모델을 다운받을 수도 있고 ComfyUI 내부 노드를 이용해서 업스케일할 수도 있다.
즉, 퀄리티를 높이기 위해서 우리는 Hires Fix를 진행할 것이다.
먼저, Hires Upscaler인 R-ESRGAN 4x+ Anime6B를 받아보자.
https://civitai.com/models/147821/realesrganx4plus-anime-6b
받은 파일은 위 페이지의 가이드대로 이름과 확장자를 먼저 변경한다.
- 기존: realesrganX4plusAnime_v1.pt
- 변경: RealESRGAN_x4plus_anime_6B.pth
그 다음 \ComfyUI\models\upscale_models 경로로 이동한 뒤 RealESRGAN_x4plus_anime_6B 폴더를 생성한다.
해당 폴더 안에 아까 다운로드 한 업스케일러 파일을 위치시킨다.
ComfyUI를 종료한 뒤 다시 실행할 예정이다.
그런데 바로 종료해버리면 우리가 지금까지 만든 노드 정보 및 이력이 모두 상실될 수 있다.
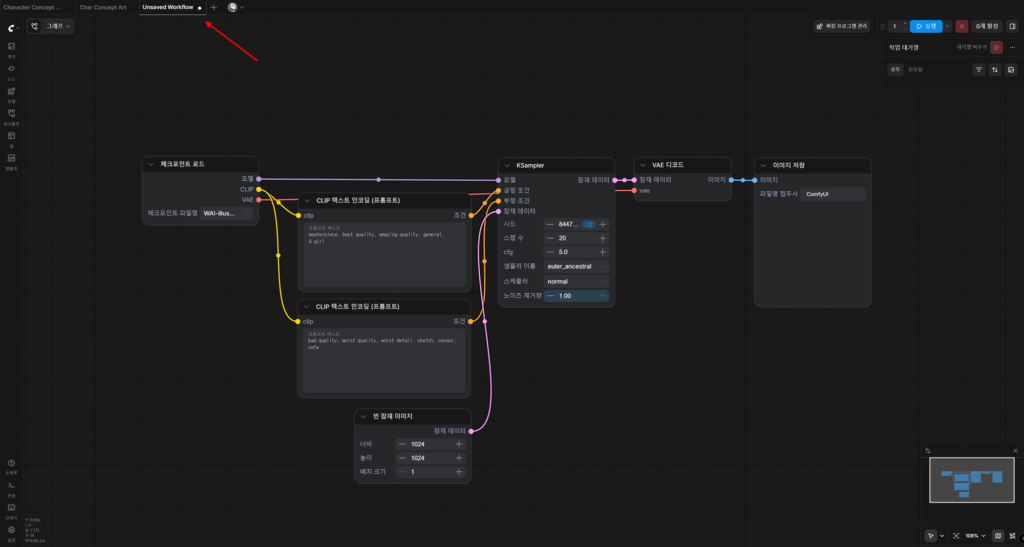
그러니 종료하기 전에 변경 이력이 있다면 모두 저장하도록 하자.
저장까지 마쳤다면 ComfyUI를 다시 실행시킨다.
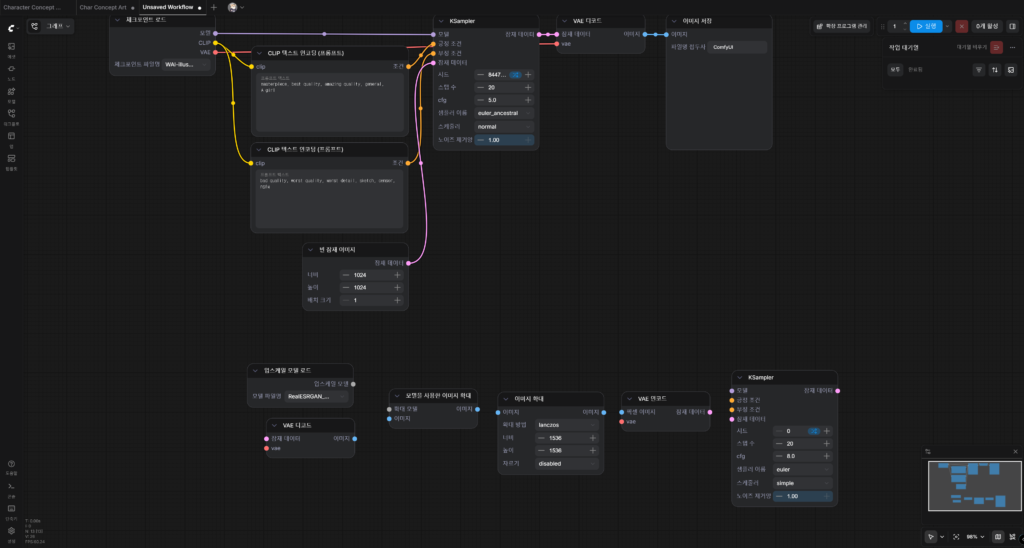
아까까지 사용하던 노드 아래, 새로운 노드를 여럿 만들어주었다.
보면 KSampler 등이 하나 더 생겼고, VAE 디코드와 VAE 인코드 등이 생긴 걸 볼 수 있다.
Hires Fix는 한 마디로 말해, 1차 KSampler에서 생성한 이미지를 업스케일하여 2차 KSampler에서 디테일업한 뒤 완성하는 방식이다.
전체 워크플로우 흐름은 대략 아래와 같다.
- 체크포인트 로드 → AI 모델 준비
- KSampler (1차) → 저해상도 기본 이미지 생성
- VAE Decode → 잠재 이미지를 픽셀 이미지로 변환
- Image Scale (lanczos) → 픽셀 단위로 1536×1536으로 확대
- VAE Encode → 확대된 이미지를 다시 잠재적 공간으로 변환
- KSampler (2차) → 확대된 구도에 AI가 디테일 추가
- VAE Decode → 최종 고해상도 이미지로 변환
- 이미지 저장 → 결과물 저장
이제 위 워크플로우대로 노드를 한번 연결해보자.
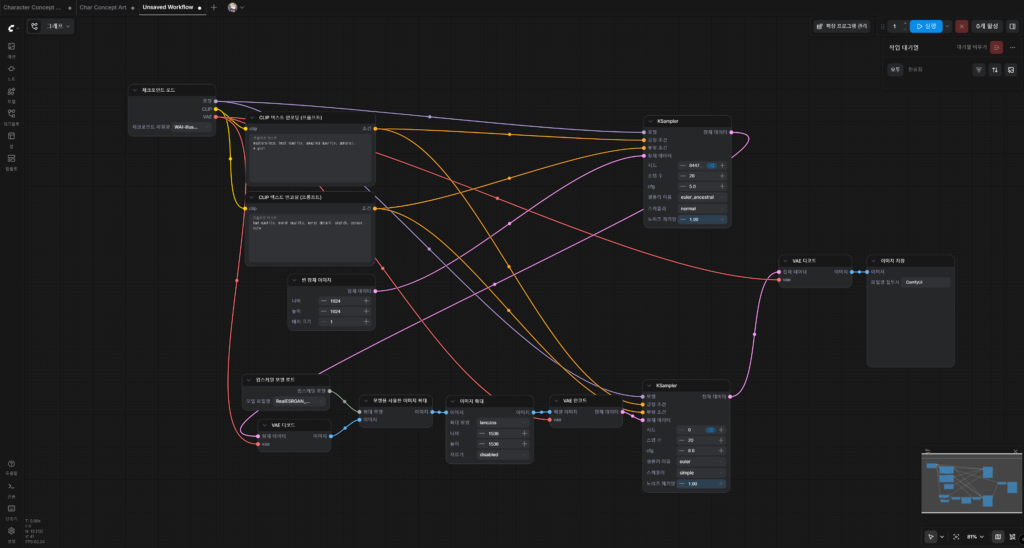
노드를 보면 한결 복잡해진 것을 알 수 있다.
하지만 색깔따라 연결한다는 개념을 바탕으로 각 노드에 빈 손이 없게 연결하면 결국 위처럼 연결 구조를 완성할 수 있다.
이제 Hires Fix에 아까 체크포인트에서 제시한 값을 한번 적용해보자.
Example images use 1024×1344.
- Hires upscale: 1.5
- Hires steps: 20
- Hires upscaler: R-ESRGAN 4x+ Anime6B
- Denoising strength: 0.35~0.5
그런데 여기 잘 보면 예시 이미지가 1024×1344 해상도로 되어있는 것을 알 수 있는데, 이 값은 어디에 적용해야 할까?
정답은 ‘빈 잠재 이미지’에 적힌 값을 너비 1024, 높이 1344로 바꿔주면 된다.
1차 이미지 생성 시 1024×1344로 생성한 뒤, Hires upscale 단계에서 1.5배로 확대한 결과를 받아낼 것이다.
이미지 확대 노드는 크게 두 가지가 있다.
하나는 원하는 결과물의 너비와 높이를 미리 지정하는 방식이 있고, 다른 하나는 배율(1.5배 등)을 지정하는 방식이 있다.
여기서 필자는 결과물의 너비와 높이를 지정하는 방식을 채택할 것이다.
배율을 지정하는 방식은 소숫점 둘째자리로에서 반올림하기 때문에 0.375배율은 0.38배로 적용해버리는 문제가 있다.
다소 번거롭지만 1024의 1.5배, 1344의 1.5배를 계산기로 구한 값인 1536×2016 해상도를 적어주도록 하자.
확대 방법은 퀄리티가 높은 이미지 확대 방식인 lanczos를 채택한다.
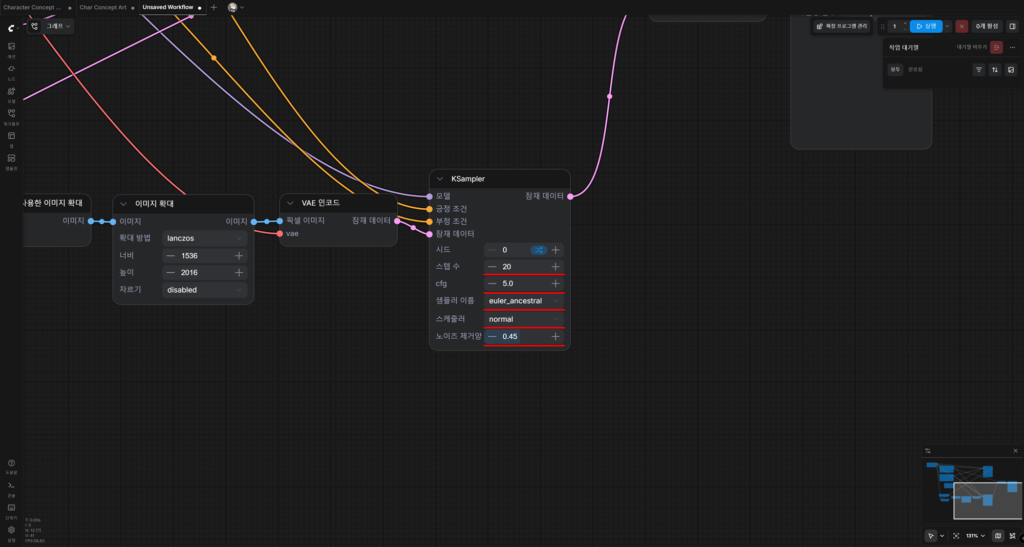
이제 2차 KSampler의 값을 바꿔줄 시간이다.
수치는 아래와 같이 적용한다.
- 스텝 수: 20
- cfg: 5.0
- 샘플러 이름: euler_ancestral
- 스케줄러: normal
- 노이즈 제거양: 0.45
여기서 핵심은, 체크포인트 가이드가 일러준 대로 노이즈 제거양을 0.35 이상 0.5 이하 값을 줘야한다는 거다.
1차 샘플러때와는 달리 2차 샘플러는 이 값을 조정해야한다는 점을 놓치지 않게 주의하자.
이제 한번 ComfyUI가 정상 동작하는지 실행 버튼을 눌러 결과를 받아보도록 하자.
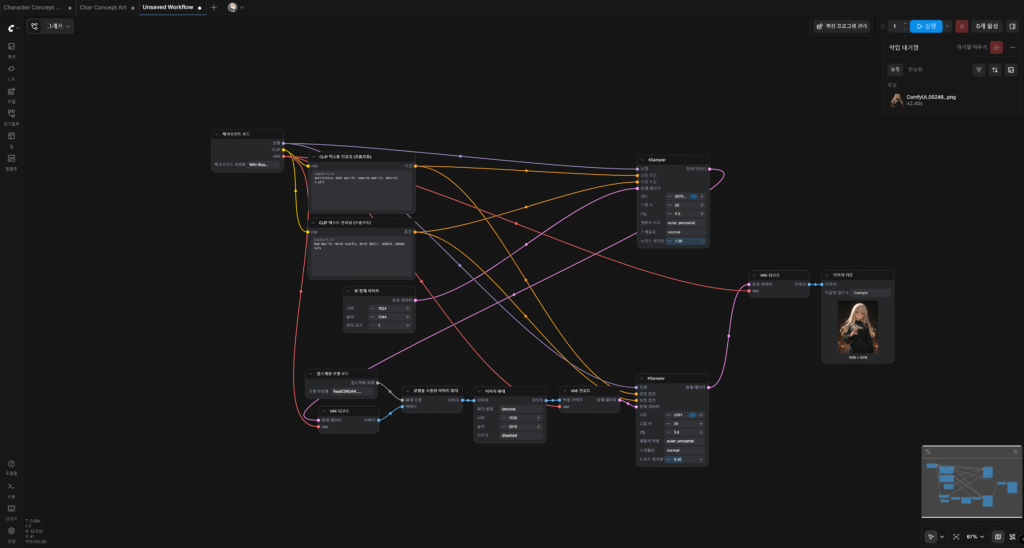
다행히 오류 없이 정상 실행되는 것을 볼 수 있었다.
LoRA와 디테일 업
LoRA는 AI 이미지를 효율적으로 미세조정하는 모델이다.
예를 들어, 내가 생성하고 싶은 캐릭터가 특정 작품에 등장하는 누구라는 식으로 명확하다고 가정해 보자.
그 캐릭터를 정확하게 구현하고 싶다고 해도 텍스트 프롬프트만으로는 원작 그대로의 모습을 재현하기에는 무리가 따를 수 있다.
이때 LoRA를 사용하면 내가 구현하고자 하는 캐릭터 이미지를 보다 정확하게 묘사해주거나, 내가 선호하는 작가의 화풍을 묘사할 수 있다.
또한 내가 원하는 포즈나 구도, 의상, 액세서리 등을 디테일하게 적용하고 싶을 때도 LoRA를 사용한다.
게임으로 비유하자면, 체크포인트가 게임 본편이라면 LoRA는 체크포인트를 더 풍요롭게 만들어주는 DLC 같은 느낌이라고 할 수 있겠다.
다양한 LoRA 중에서 두 개만 여기서 소개해보고자 한다.
748cm LoRA는 “748cm”이라는 특정 작가/스타일의 비주얼 특성을 재현하기 위해 만들어졌다.
프롬프트에 748cmstyle이라는 키워드를 입력하면 해당 작가의 스타일이 반영된다.
해당 작가의 화풍을 선호하는 경우에는 이렇게 특정 작가의 LoRA를 반영하면 원하는 결과물에 더 가까워질 수 있다.
한편 Smooth Detailer Booster는 스타일을 바꾸는 것이 아니라 전반적인 이미지 품질을 끌어올리는 도구에 가깝다.
주로 색상, 그림자, 조명 등, 결과물의 품질 자체를 좀 더 다채롭게 구성해주는 기능을 한다.
LoRA를 사용할 땐 단독으로 하나만 사용해도 되지만, 위에서 소개한 두 개의 LoRA처럼 서로의 영역이 중복되기보다는 상호보완의 기능을 하는 경우에는 두 개 이상 연결해서 사용하기도 한다.
단, LoRA를 많이 연결할수록 각 LoRA의 가중치를 적절하게 조절해줘야 한다.
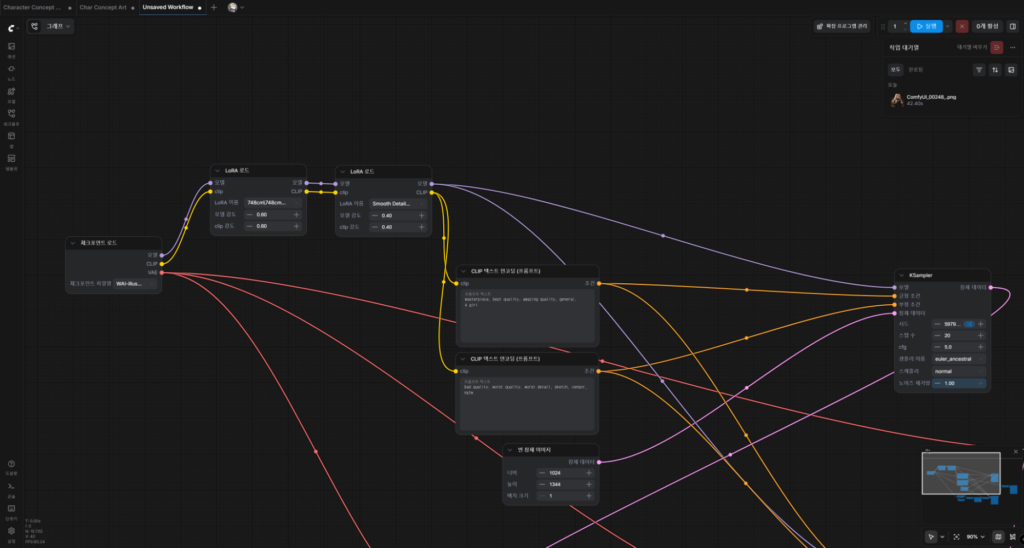
LoRA는 체크포인트와 Clip 텍스트 인코딩 사이에 위치시킨다.
이미 체크포인트 로드와 Clip 텍스트 인코딩 노드 사이가 연결되어 있다면 그것을 끊어주고 그 사이에 LoRA를 연결해주면 된다.
참고로 LoRA에서 뻗어나가는 ‘모델’은 KSampler와 연결되는데, 1차 샘플러와 2차 샘플러 각각 연결해주어야 하는 것에 유의한다.
놓치지 말아야할 것이 있는데, 각 체크포인트는 LoRA를 비롯한 각 모델과 호환성 이슈를 유의해서 사용해야 한다는 점이다.
만약 내가 사용하는 체크포인트가 Illustrious 계열인데 LoRA는 SD1을 받으면 호환되지 않는다.
이런 경우 퀄리티가 저하된 결과물을 받거나 생성 속도를 굉장히 늘리는 등 작업에 부정적인 영향을 초래할 수 있다.
위의 두 LoRA는 WAI-Illustrious-SDXL에 호환되는 ‘for Illustrious’ LoRA이므로 그대로 사용해도 된다.
Clip Skip과 체크포인트 Illustious
CLIP Skip은 AI가 텍스트 프롬프트를 이해하고 이미지로 변환하는 과정에서 CLIP 모델의 어느 레이어까지 사용할지 결정하는 설정값이다.
Stable Diffusion 1.5는 12개의 레이어를 가지는데, 이미지를 생성할 때 프롬프트가 각 레이어를 거치며 상(image)을 점점 구체화하는 식이다.
예) 1번 레이어: 여자, 2번 레이어: 젊은 여자, 3번 레이어: 젊고 예쁜 여자 …
대부분의 애니메이션/게임 일러스트를 위한 체크포인트는 Clip Skip 2(-2)에서 학습되어 있다.
생성하고자 하는 이미지가 ‘서브컬처풍 미소녀’이므로, 우리는 Clip Skip값을 2(-2)로 변경하는 노드를 추가해줄 것이다.
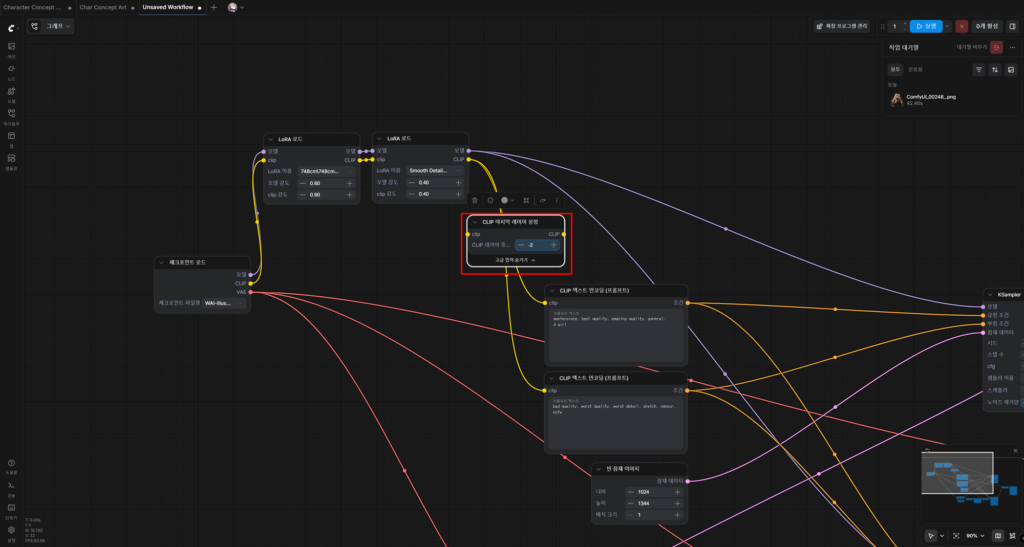
이렇게 연결하면 최종 형태는 아래와 같이 완성된다.
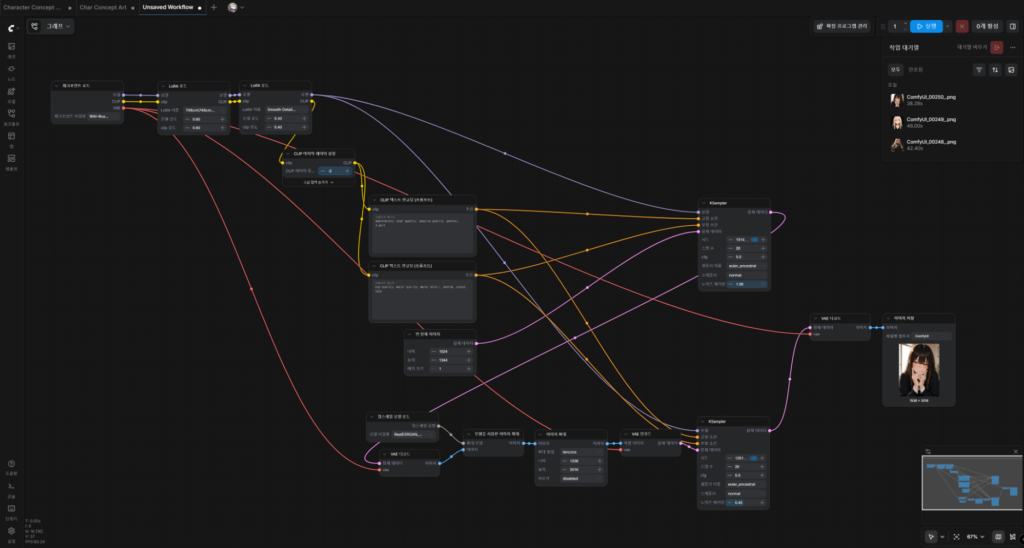
글을 마치며: 물 속의 미쿠
이제 지금까지 세팅한 것을 바탕으로 WAI-illustrious-SDXL의 대표 이미지인 ‘물 속의 미쿠’를 한번 만들어 보자.
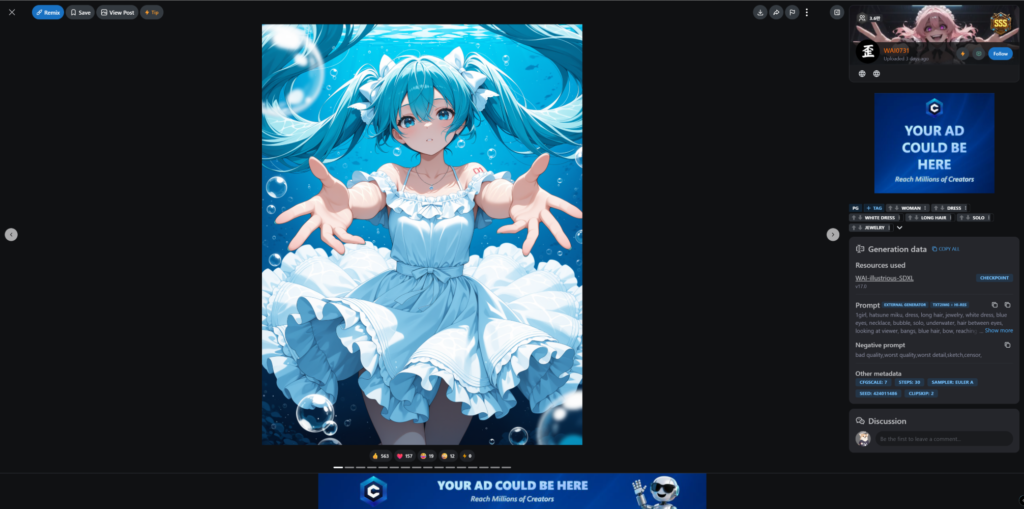
Civitai 우측을 보면 해당 이미지의 Generation Data를 확인할 수 있다.
저기에 있는 프롬프트를 복사해서 내 ComfyUI 프롬프트 붙여넣고, Other Metadata에 적힌 값도 저기에 있는 값을 따와서 이미지를 생성해보자.

그러면 위처럼 레퍼런스 이미지와 유사한 고퀄리티의 ‘물 속의 미쿠’ 이미지를 얻을 수 있다. (위는 필자가 생성한 이미지)
다음 글에서는 이번에 만든 ‘캐릭터 일러스트 제작’ 프로젝트를 기반으로, 게임 컨셉 원화 시트 제작 방법 및 프롬프트 입력 가이드에 관해 다룰 예정이다.
답글 남기기